
채팅 API 설계가 어려운 이유
🐜 단순 CRUD가 아니다
보통 기계적으로 단순 CRUD를 설계할 경우 최적화 방법도 비교적 간단합니다. 하지만 채팅은 CRUD 하면 일반적으로 떠올리는 애플리케이션은 아닙니다. 내부에 상태도 엄청 많고 (읽음/안 읽음, 접속 중/미접속 중, 타이핑 중 등) 실시간성이 크게 요구됩니다.
🐜 Read - Write 비율이 비슷하다
보통의 경우 Read가 Write에 비해 한참 적습니다. 그래서 많은 설계 문제에서의 해결책은 주로 정확성을 조금 희생해 (Cache등을 둬서) 읽기의 부담을 줄이는 게 끝입니다.
하지만 채팅의 경우 내가 상대방이 보내는 문자들을 읽는 것 만큼 나도 보냅니다. 즉, 읽기/쓰기의 비율이 거의 1:1에 가까워서 우리가 흔히 알고 자주 사용하던 많은 최적화 기법을 쓰지 못하는 경우가 많습니다.
Version 1 - 가장 처음 생각한 구조
모든 설계 문제는 유저가 많아져 서버의 부담이 늘어나는데서 시작합니다.
그래서 저는 우선 유저가 10명도 안 될 때 어떻게 설계할 것인지를 생각하는 것도 좋아합니다. 회사에서 코딩을 하면 MAU 몇 맥만 명을 고려하는게 의미가 있겠지만 보통 개인 프로젝트에서 코딩을 하면 MAU 100명도 감지덕지인 경우가 많기 때문입니다.
그렇다면 아무런 부담이 없다면 채팅 API를 어떻게 설계할까요? 이렇게 되면 사실 채팅 API 설계는 단순한 CRUD가 돼 버립니다.
- 채팅을 보낼 때는 그냥 다른 평범한 데이터 저장하는 것과 똑같이 DB에 저장하고, 채팅을 볼 때도 똑같이 DB에서 조회하기
- 알림 등은 주기적으로 Polling 해서 새로운 메세지가 없는지 확인하고 있으면 보내기
- 타이핑 중은 타이핑 시작하면 DB에 flag 둬서 업데이트 하기

Version 2 - 발전시키기 : WebSocket 사용하기?
여기서 쪼금 발전시킨다면 HTTP 대신에 WebSocket을 사용할 수 있습니다.
WebSocket은 1번 연결을 맺어두고 (Handshake를 하고) 그 연결을 계속 재사용하기 때문에 HTTP에 비해 빠릅니다. 게다가 양방향 통신이기 때문에 Polling을 하면서 불필요하게 서버 자원을 낭비할 필요도 없습니다.
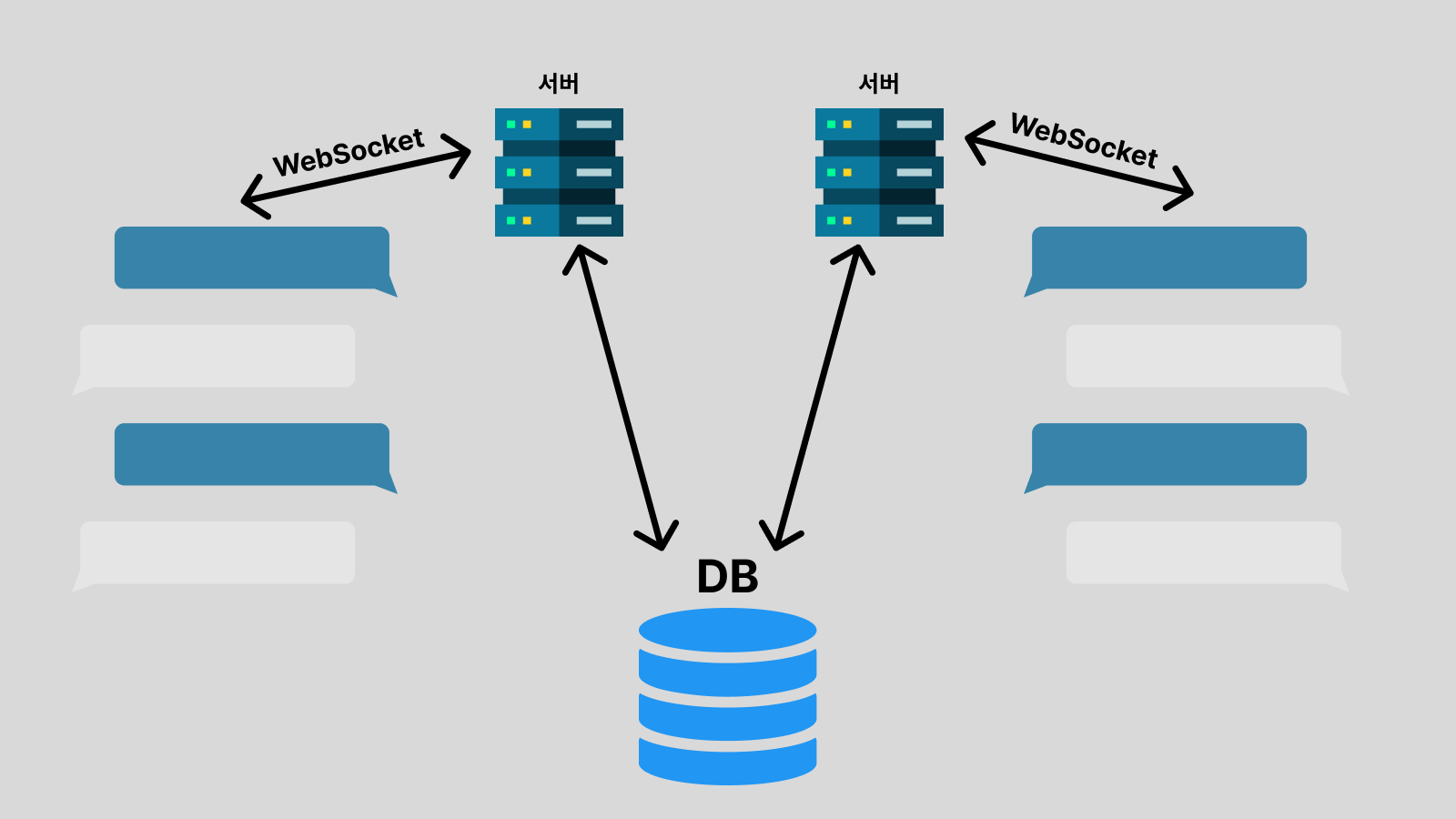
Version 3 - DB 부하 줄이기
위의 구조는 결국 주기적으로 DB에 질의해서 새로운 메시지가 생겼는지 확인해야 하기 때문에 DB에 부하가 장난이 아닐 겁니다. 서버 아키텍처에서 보통 가장 귀중한 자원은 DB이기 때문에 DB의 부하를 줄이는 게 핵심입니다. 이것도 여러 방법이 있을 거 같습니다.
🐜 같은 서버에 접속하게 하기
우선 웬만큼 트래픽이 많이 나오더라도 DB를 질의하지 않고 채팅 접속자들을 같은 서버를 바라보게 하면 많은 게 해결됩니다. 메모리상에서 메시지 송수신을 해결하고, 주기적으로 DB에 flush 하는 방식 정도를 사용하면 될 거 같습니다. 물론 이렇게 하면 안정성은 떨어집니다. 서버가 갑자기 내려가면 데이터가 유실될 수도 있고, 재접속까지 시간이 걸릴 수도 있습니다.

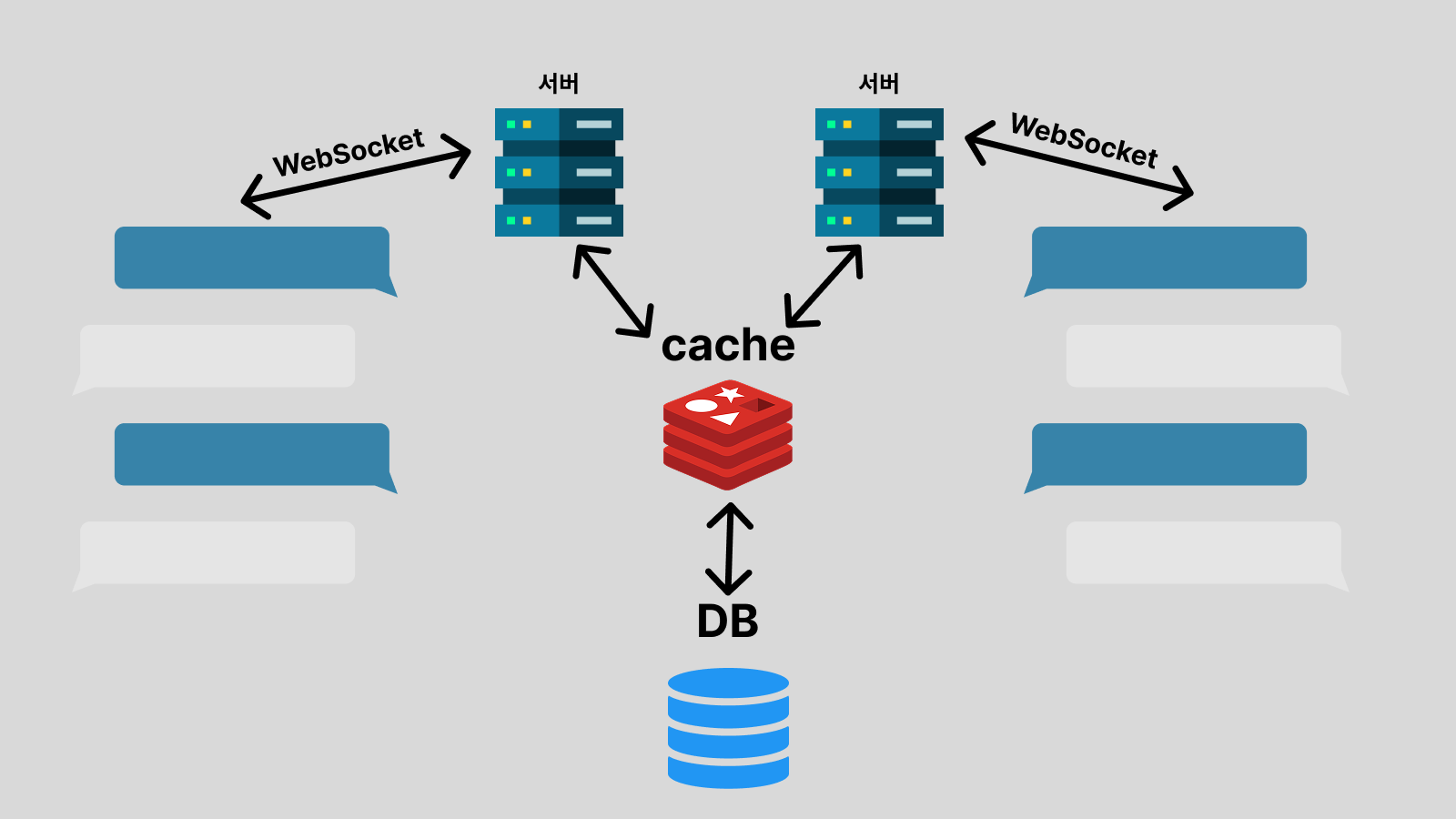
🐜 Cache 두기
같은 서버에 접속하게 하는 건 너무 번거롭고, 서버가 죽으면 복구에 오랜 시간이 걸리는 게 마음에 안 들 수 있습니다. (게다가 같은 서버에 접속해야 한다면 사람이 많은 그룹챗의 경우 힘들 수도 있습니다.) 그럴 경우에는 다른 서버에 접속할 수 있다는 건 유지하면서 Redis 같은 캐시를 도움 할 수 있습니다.
이런 식으로 하면 Cache 서버가 죽지 않는 이상 장애가 날 일이 없고, DB와 캐시 사이의 동기화를 아예 다른 서버 인스턴스한테 맡겨 실제 채팅을 담당하는 서버 인스턴스의 부하를 줄일 수 있습니다.
Version 4 - Message Queue를 사용해 SPOF 없애기
위의 모든 방법은 결국 저장소 1곳에 메시지를 저장하고, 새로운 메시지가 왔는지 확인하기 위해 그 저장소를 계속 질의하는 방식이였습니다. (저장소를 DB를 쓰냐, Cache를 쓰냐의 차이일 뿐) 결국 이 저장소가 무너지면 모든 시스템이 무너집니다. 이런 구조 자체를 탈피해서 저장소는 오래된 메세지를 볼 때만 사용하고 최신 메세지가 있을 때는 이걸 통지받는 구조가 더 현명한 구조입니다. 여기에 가장 적합한 게 Kafka 같은 Message Queue입니다.
Kafka는 굉장히 고가역의 트래픽도 견딜 수 있고 여러 곳에서 구독이 가능하기 때문에 중앙의 저장소에 질의하는 게 아니라 필요한 시스템이 (알림, 메시지 서버, 활동 탐지 서버 등) 알아서 구독할 수 있어서 중앙 저장소의 부하를 굉장히 줄일 수 있습니다.

'👨💻 프로그래밍 > 📦 Backend' 카테고리의 다른 글
| Kotlin Sequence (스퀸스) 에 대해 알아보자 (0) | 2024.02.04 |
|---|---|
| 핵사고날? 클린 아키텍처? DDD? (0) | 2024.01.28 |
| GraalVM 알아보기 (0) | 2023.12.09 |
| CQRS (Command Query Responsibility Segregation) 알아보기 (1) | 2023.12.08 |
| 😵 1달동안 MSA 다시 Mono로 전환한 후기 (0) | 2023.11.13 |



