열심히 만들고 있는 책과 관련된 사이트에 책을 검색할 수 있는 기능을 넣었습니다. (booksitout.com에서 사용해 볼 수 있습니다)
평소 책을 많이 읽는 편이라 도서관, 구독 서비스, 중고책 등을 한 번에 검색하면 편리하겠다 해서 넣었고, 좋은 아이디어라 생각했습니다.
하지만 문제가 있었습니다. 느려도 너무 느리다는 것입니다. 아래는 Zipkin을 사용해서 검색 속도를 측정한 것인데, 최고 9초가 걸립니다.

검색 속도를 최적화 하기 위해 제가 헤매고 실수하며 내린 결정들과 그 근거들을 소개해 보겠습니다.
Spring Webflux, Kotlin Coroutine으로 Refactoring
가장 먼저 비동기적으로 요청하도록 개선했습니다.
사용자가 거의 없으니 영향이 크지는 않겠지만, 전체를 받아오는데는 오래 걸려도 처음 화면을 보는 시기를 최대한 앞당기자는 전략이였습니다.
search 마이크로서비스는 Kotlin을 사용하고 있었기에 Kotlin Coroutine을 사용해 비동적으로 요청하도록 개선하고, Spring Webflux를 사용해 결과를 내보낼 때도 비동기적으로 응답하도록 개선했습니다.
캐시 도입 (Redis)
우선, "속도 최적화" 하면 가장 먼저 떠올릴 캐싱을 도입 해 봤습니다.
중고책은 계속 재고가 변하니 캐싱을 오래 해 둘 수 없지만, 도서관 같은 경우는 책이 없어지지 않으니 만료기간을 오래 두고 캐싱을 해 두면 의미있는 속도 변화가 있을 거라 확신하고, Redis를 도입했습니다.
Redis의 key는 대소문자 구분을 없애고, 공백도 없애는 등 기본적인 조치는 했습니다.
그 결과 정말 의미있는 속도 변화가 있기는 했습니다. 9초 걸릴 query도 Cache Hit인 경우 무려 0.21초로 단축됐습니다.
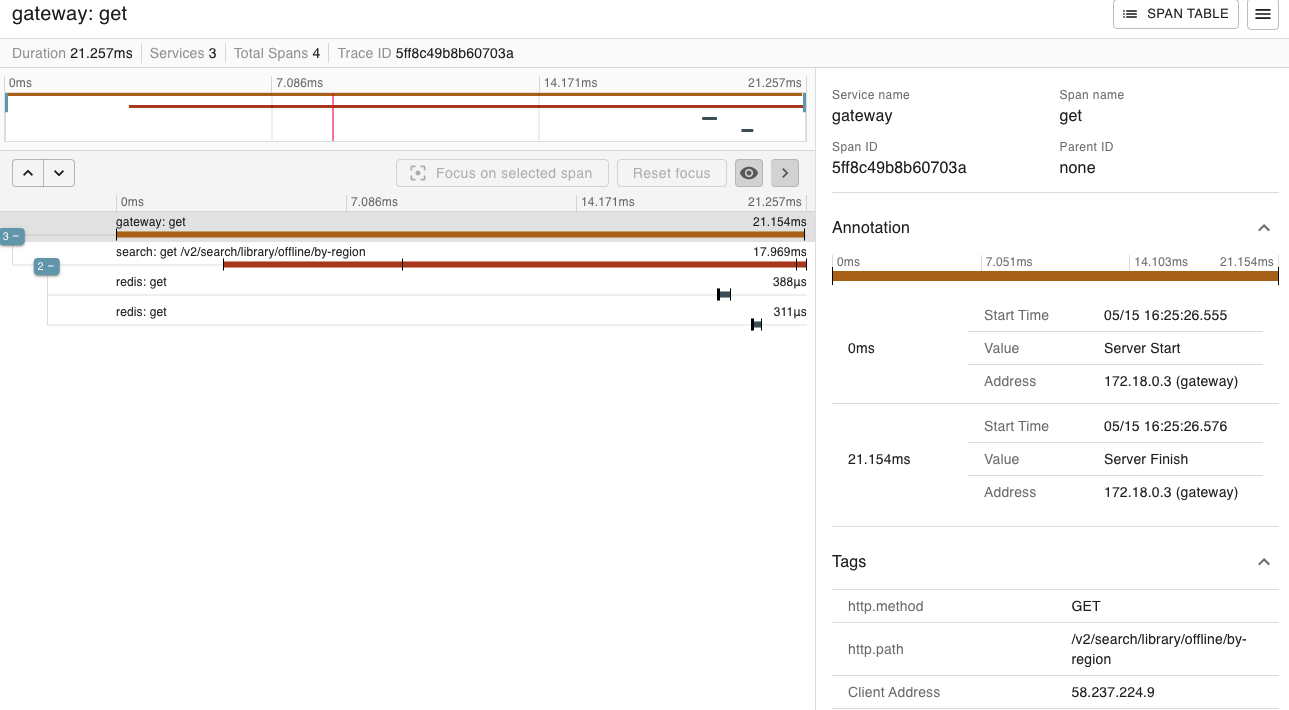
하지만 여전히 문제가 많았습니다.
- Cache Miss인 경우 최고 10초가 걸리니 여전히 해결이라 부르기는 민망합니다.
- 가장 적게 변할 거 같은 도서관 조차 유효기간 길게 설정할 수 없습니다. 있는 책이 없어지지는 않아도, 새로운 책은 계속 들어오니 길어도 1달이면 모든 Cache가 사라집니다.
- 도서관의 대출현황 (지금 도서관에 있는지, 누가 빌려 갔는지, 예약은 가능한지)는 실시간성이 중요해서 보유도서 정보는 Caching 해도, 결국 요청을 해야 합니다.
처음에는 말도 안 되는 해결책을 생각했습니다. 그 중 일부는 정말 황당합니다.
- AI를 사용해서 Query를 예측해서 미리 캐싱 해 둬야 하나?
- 알라딘에서 카테고리별로 100위 정도까지 Batch를 매 시간 돌릴까?
하지만 모두 근본적인 해결책은 아닌거 같았습니다. 이쯤에서 감에 의존하지 말고 정말 철저하게 분석하고 계산해 보자고 결심했습니다.
병목 현상 분석하기
여태까지는 API나 웹 크롤링해서 응답을 받아오고, 전달하기까지의 과정에서 최대한 병목을 줄여보려 했지만, 하면 할 수록 이게 근본적인 문제가 아니라는 생각이 들었습니다. 그래서 실질적인 병목현상을 분석해 봤습니다.
우선, 검색을 할 때는 크게 6개의 카테고리에서 검색을 수행합니다.
- 유저가 책잇아웃(포트폴리오)에서 자체적으로 등록한 책 (자체 DB)
- 오프라인 도서관 (공공 API)
- 전자 도서관 (웹 크롤링)
- 구독 서비스 (오픈 API, 웹 크롤링)
- 중고 온라인 (알라딘 오픈 API, 웹 크롤링)
- 중고 오프라인 (알라딘 오픈 API, 웹 크롤링)
여태까지는 막연하게 모든곳에서 비슷한 병목이 일어났을거라 생각했지만, 예상과는 달리 오프라인 도서관을 검색하기 위한 공공 API에서 대부분의 병목이 발생하고 있었습니다. 물론, 오프라인 공공 API의 병목을 제거해도 검색 속도는 1~2초로 빠르지는 않았지만, 5초, 10초가 걸릴 일을 없어 보였습니다.
하지만, 공공 API는 제가 만든 것도 아닌데 성능을 개선할 수가 없었습니다. 그래서 내린 해답이 "그냥 웹 크롤링을 하자" 였습니다. 이게 제가 검색 속도를 최적화하며 내린 최악의 실수였습니다.
공공 도서관 사이트 웹 크롤링 하기
공공 API를 쓰며 불만이 많았습니다. 그 중 일부만 나열하자면
- API 문서에 적힌 대로 동작하지 않는 경우가 너무 많았습니다. Parameter를 제대로 썼는대도 응답이 제대로 안 와서 왜인지 도저히 몰랐는데, 알고보니 대소문자가 API 문서에 적힌 것과 달랐습니다.
- JSON으로 응답을 요청했는데 Header에는 application/xml로 응답이 와서 Jackson이 인식을 못 한 경우도 있었습니다.
- endpoint 디자인이 이상했습니다. 굳이 나눌 필요가 없어 보이는데 세세하게 나눈 경우도 있었고, query로 도서관을 받아오는 기능이 당연히 있을 거 같았는데 그건 없고 isbn으로 받아오는 endpoint만 있어 isbn을 우선 검색하고 하나하나 isbn으로 도서가 있는 도서관을 받아와야 해서 시간 복잡도가 O(n^2)이였습니다. (이는 나중에 Caching으로 개선해서 큰 문제는 없었습니다.)
그래서 막상 웹 크롤링을 하자고 결심하니 오히려 예측 가능한 범위에서 오류가 일어나고, 원하는 데이터를 받아올 수 있다고 생각하니 마음이 편했습니다.
하지만 제 생각 이상으로 공공 도서관 사이트는 엉망이였습니다.
영등포구 도서관으로 예시를 들자면, 도서관에서 검색할 때의 URL은 https://www.ydplib.or.kr/intro/plusSearchResultList.do 입니다. URL에 Query가 없고, POST 방식으로 전달합니다. 즉, 주소를 복사/붙여넣기 하면 오류가 납니다.
더 큰 문제는, 서울시의 경우 구별로, 같은 구여도 관활하는 기관 별로 (교육청, 서울시, 국회 등) 도서관 사이트가 다 달랐습니다. 또, 도서관 별로 코드가 있는데 여기에도 아무런 규칙이 없어서 JS를 일일히 분석하면서 알아내야 했습니다.
거기다 일부 사이트의 경우 JS 파일 최적화를 안 해 놔서 사이즈가 너무 큰 데다, JS파일을 모두 로딩 하고 API 요청을 하는 경우도 있어 속도가 공공 API보다 오히려 더 느렸습니다.
영등포구, 구로구, 마포구, 강남구 4곳 째 이 작업을 하고 있으니, 뭔가 크게 잘못된 것을 깨달았습니다.
직접 DB를 구축하면 안 될까? 데이터에 기반한 결정하기
결국 공공 API나 공공 웹 사이트에서 병목 현상이 발생하고 있는데 주기가 짧아 Caching을 해도 부족하니, 직접 DB를 구축하지 않는 한, 더 이상 성능을 최적화 할 방법은 없었습니다. 처음에는 전국의 도서관 데이터에 관한 DB를 구축한다는 발상이 너무 황당하고 말도 안 된다고 생각해서 고려도 안 했지만, 많은 시행착오를 겪고 이 방법이 가장 최선의 해결책이라 깨닫고, 무작정 부정하지 말고 실제 계산을 해 보기로 했습니다.
Batch 작업을 한다면 얼마나 걸릴까?
집 근처의 비교적 큰 선유 도서관을 기준으로 잡아봤습니다. 선유 도서관의 소장 도서 수는 87,000권 정도입니다. 1년에 약 1,000권 정도가 추가되는거 같았습니다.
공공 API는 한 번 호출 시 100권의 도서를 요청할 수 있고, 하루 500건 정도 호출 가능합니다. (더 늘릴 수는 있음) 즉, 하루에 50,000권을 호출해 저장할 수 있습니다. 비교적 큰 도서관도 하루면 모든 도서를 저장할 수 있으니, 1달 정도면 서울의 모든 도서관은 저장할 수 있을거 같습니다.
생각보다 비현실적인 숫자는 아니라 좀 놀랐습니다.
DB에 저장한다면 어느 정도 용량이 필요할까?
Batch 작업에는 시간이 생각보다 얼마 안 걸려도, 결국 DB에 저장해야 하는데, DB를 운영하는데 비용이 너무 많이 들면 안 될거 같았습니다. 그래서 DB에 모든 책을 저장하면 얼마 정도 걸릴까도 계산해 봤습니다.
도서 정보는 정규화 시킨다고 가정했습니다. 도서관 정보도 정규화 시킨다고 가정했습니다
도서관 정보는 얼마 안 될 테니 제외하고, 책 정보 + 도서관 소장 책 정보만 계산했습니다. 또, 계산의 편의성을 위해 VARCHAR인 경우 최댓값을 차지한다고 가정했고, Index는 무시했습니다.
| 제목 | VARCHAR(30) | |
| 부제목 | VARCHAR(50) | |
| 저자 | VARCHAR(30) | |
| isbn | TINYINT(13) | |
| 표지 URL | VARCHAR(100) | |
| 장르 | VARCHAR(10) | |
| 출간일 | DATE |
- 1개의 데이터 당 237 byte 정도
- 1GB = 1,000,000,000 byte -> 1GB를 차지하기 위해서는 4200개
| 책 위치 | VARCHAR(30) | |
| 책 FK | MIDINT | |
| 도서관 FK | SMALLINT | |
| 등록일자 | DATE |
- 1개의 데이터 당 20 byte 정도
- 1GB를 다 차지하기 위해서는 500만개 정도의 데이터 필요
- 선유도서관 기준 1GB 당 57개의 도서관
계산에 오차가 많아 현실에서는 다르겠지만, 이것도 생각보다 용량을 많이 차지 안 해서 놀랐습니다.
AWS RDS 요금
Batch 작업에 걸리는 시간이나, DB 용량은 생각보다 적게 차지한다고 해도, 현실적인 문제로 Cloud 요금이 너무 많이 나오면 의미가 없습니다. 그래서 간단하게나마 AWS RDS를 사용하는 기준으로 1달에 얼마 정도의 요금이 나올지 계산 해 봤습니다.
AWS 요금 체계를 간단하게 공부해 본 결과, 생각보다는 저렴했습니다.
- 저장 : 1달에 1GB 당 $0.1
- 요청 : 100만 Request 당 $0.2
상황에 따라 계속 바뀌겠지만, 아래의 요금을 기준으로 계산해 보겠습니다.
저장
- 서울 지역 도서관을 다 저장하면 10GB는 필요
- 10GB * $0.1 = $1 -> 한 달에 Storing에 1달러가 듭니다.
- 전국 도서관을 저장한다고 하면 어림잡아 $10
요청
- DAU 1000명 (꿈 같은 숫자) * 1명당 하루 평균 Request 100개 = 100,000개
- 100,000개 * 30 = 300백만개 = $0.6
결론 : 결국 직접 DB를 구축할 수 밖에 없다
검색을 최적화하는 과정을 거치면서, 힘든 일도 많았지만 많은 기술적 성장을 했습니다. 이미 있는 정답을 책에서 배우고 이해하는게 아니라, 직접 고민하고 계산해 보니 문제 해결력이 늘었습니다.
무엇보다, 기술적 결정을 내릴 때 장단점을 미리 생각해 보고, 직접 계산해 보고, 고민하고 내려야 한다고 고생하며 배웠습니다. 귀찮아서 대충 한 결정들이 쌓여 레거시 코드가 되고, 큰 짐덩이가 된 걸 보고 많은걸 느꼈습니다.
분명 혼자서 하고 있는 프로젝트인데 반년 정도 열심히 만드니 레거시 코드가 생기고, 다양한 경험을 해서 정말 재밌습니다.
'👨💻 프로그래밍 > 📦 Backend' 카테고리의 다른 글
| 🔥 Hot Ranking 알고리즘, Spring Batch로 구현하기 (feat. Strategy 패턴) (0) | 2023.05.18 |
|---|---|
| Spring Cloud Config로 Config 서버 구성하기 (0) | 2023.05.02 |
| 통계를 처리하기 위한 Table을 만드는 설계는 바람직할까? (0) | 2023.04.28 |
| 스프링 서큐리티(Spring Security) 구조 이해하기 (0) | 2023.04.11 |
| 마이크로서비스(MSA)를 쓰는 이유 (0) | 2023.03.28 |



